Image classifier
Strawberry, cherry, tomato image classifier
Made with: Python, Scikit-learn, Keras, Tensorflow
The image classification is a university project in AI that can help identify if an image is a strawberry, cherry, or tomato. This classifier was developed and trained through thousands of images using many different tools to help remove redundant data and optimize its classification success.
The Process
- Overview -
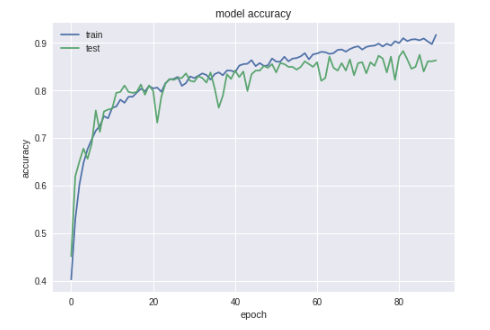
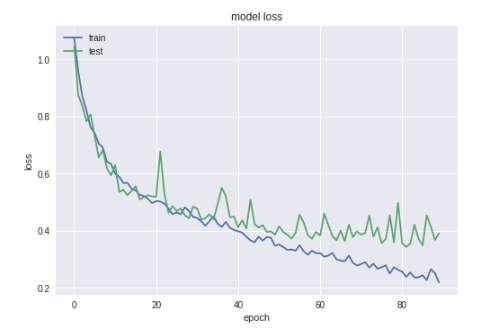
The goal and problem of this project are to create an image classification model that is able to identify and distinguish the differences between a cherry, tomato, and strawberry so that it can correctly classify an unknown image when the model is used. To do this I had created a convolutional neural network that uses multiple layers to train the model using 4500 images with an 80/20 split for train and test sets and improving the accuracy by adjusting the training methodology using techniques such as optimization methods, parameter tuning, etc. I then compared this to a baseline model to compare and contrast how my model measures toward the baseline in terms of image classification results.
- Problem investigation -
For this problem, I had looked through the data specifications using data exploratory analysis to identify areas that would negatively affect my training process. During this, I had looked through the image format such as the size, image formats, parameters of the images etc. Without even sizes and same image formats, it would not be able to classify the images correctly when creating a CNN. I had also checked and made sure that all the different classes that were to be trained had an even distribution of classes so that the dataset is balanced between the different class classification types.
- Preprocessing -
For preprocessing I had also looked through the whole data set scanning for outlier images/images that were not relevant and had no correlation towards the dataset or images that were too nosy, too large to see anything, too small, and those that were unrecognisable even to human eyes Eg: there was a picture of a family that had no signs of a strawberry even though it was classed as a strawberry. Low-quality data will lead to low-quality results especially if the data does not represent real-world applications as the model won’t be able to extract features that would not work in the real world.
- Methodology -
When it came to training my data for my convolutional neural network, I had a lot of trial and error when improving my model. This included playing around with the number of layers I added to the network, tuning parameters, fixing overfitting and underfitting problems, etc. At first, I had started with a simple convolutional network consisting of 3 layers, and building up until a larger network was formed.
- Optimization -
Loss Function :
I had experimented with different loss functions available in keras including the different cross-entropy loss functions such as sparse categorical cross entropy, binary cross entropy, and Poisson.
Optimization function: Initially, the optimization method was set to Stochastic gradient descent (SGD) where it gave fairly average results in terms of accuracy and loss for my model. However, I noticed that the amount of time it took to train to what accuracy it gave me, simplify was not good in terms of how it was training the data. I had changed to the Adam optimizer and seen much larger improvements especially how good it was at learning and improving the model at smaller amounts of training.
Regularization strategy: When creating models with my CNN, I had tried to improve my results that I had gotten through the different models I had created. One of the parts that I had used to improve this was to use regulziation mainly the use of the dropout function to prevent the issue of overfitting in my model.
Activation function: I used the softmax activation method, it correctly trains my model. This is because the softmax activation method is used for multi-classification tasks which are good for my dataset when it can be classified into 3 different classes. When it is used, it computes the probability range from 0 - 1 where it acts similarly like a max layer function that will increase and choose the maximum value of the previous layer to compare with the other value.
Hyper-Parameter settings: I had tuned the images such that it would be able to have a full view of rotation, a shear range of around 0.2, allow flipping and rotation as well as rescaling and a zoom. Through this data augmentation and setting the parameters for it, it allows for a more accurate result with more dataset and images to use in my model. I had split my dataset into a ratio of 80 / 20 for training and validation. This allowed me to see how my training process was doing through 20% of images which the model did not know about / is not trained on.